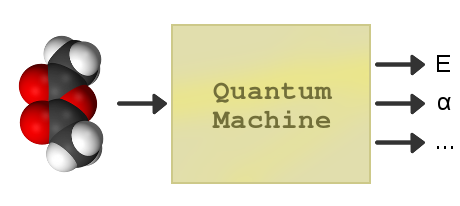
 This website aims to collect useful resources (datasets, benchmarks, etc.) for accelerating the development of a “quantum machine”, a machine that can quickly and accurately simulate quantum-chemical systems from first principles. Such quantum machine typically relies on induction (or interpolation) in order to generalize to other systems of particles. A conceptual illustration of a quantum machine in the context of structure-property prediction is shown on the left.
This website aims to collect useful resources (datasets, benchmarks, etc.) for accelerating the development of a “quantum machine”, a machine that can quickly and accurately simulate quantum-chemical systems from first principles. Such quantum machine typically relies on induction (or interpolation) in order to generalize to other systems of particles. A conceptual illustration of a quantum machine in the context of structure-property prediction is shown on the left.
News
- 2020-04-29: Release of the QMspin database.
- 2016-11-07: Release of several MD datasets.
- 2016-05-04: Release of the QM8 dataset.
- 2014-08-18: Release of the QM9 dataset.
- 2013-04-05: Release of the QM7b dataset for prediction of multiple molecular electronic properties (atomization energies, HOMO/LUMO eigenvalues, polarizability, etc.) from molecular geometry.
- 2013-01-01: Release of the QM7 dataset for prediction of atomization energies from molecular geometry.
Motivation
Modern DFT-based quantum chemistry methods are enabling the systematic simulation of quantum chemical systems with impressive results in molecular structure-property mapping, molecular dynamics or simulation of chemical processes at the quantum level. Yet, the same methods are often application-specific, and their multiple hyperparameters have unpredictable effects on model’s accuracy. On the other hand, machine learning and other inductive methods offers a principled way of minimizing the risk of a prediction problem and are able to extract automatically the desired problem-relevant subspace from the input representation. The resulting “quantum machine” should not only produce results which compete in terms of accuracy with DFT-based methods, they should also provide a dramatic acceleration of quantum chemical simulations, paving the way for a better understanding of the underlying computational problem.
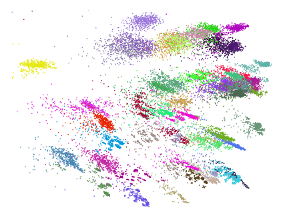 The figure on the right depicts a two-dimensional representation of a small subset of GDB-13 (a dataset of small synthetically accessible organic molecules). Each color cloud represents a set of adjacency matrices (or Coulomb matrices) obtained with different atoms indexing of the same molecule. This picture suggests a rich and highly multimodal problem with variations at multiple scales and with multiple regularities. Characterizing the dataset and its multiple regularities gives rise to a challenging machine learning problem.
The figure on the right depicts a two-dimensional representation of a small subset of GDB-13 (a dataset of small synthetically accessible organic molecules). Each color cloud represents a set of adjacency matrices (or Coulomb matrices) obtained with different atoms indexing of the same molecule. This picture suggests a rich and highly multimodal problem with variations at multiple scales and with multiple regularities. Characterizing the dataset and its multiple regularities gives rise to a challenging machine learning problem.